[Service] Type=notify ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin= ExecReload=/bin/kill -s HUP $MAINPID TimeoutSec=0 RestartSec=2 Restart=always # Note that StartLimit* options were moved from "Service" to "Unit"in systemd 229. # Both the old, and new location are accepted by systemd 229 and up, so using the old location # to make them work for either version of systemd. StartLimitBurst=3 # Note that StartLimitInterval was renamed to StartLimitIntervalSec in systemd 230. # Both the old, and new name are accepted by systemd 230 and up, so using the old name to make # this option work for either version of systemd. StartLimitInterval=60s # Having non-zero Limit*s causes performance problems due to accounting overhead # in the kernel. We recommend using cgroups to do container-local accounting. LimitNOFILE=infinity LimitNPROC=infinity LimitCORE=infinity # Comment TasksMax if your systemd version does not support it. # Only systemd 226 and above support this option. TasksMax=infinity Delegate=yes KillMode=process
[Install] WantedBy=multi-user.target
1 2 3 4 5 6 7 8 9 10 11 12 13
# cri-docker.socket [Unit] Description=CRI Docker Socket for the API PartOf=cri-docker.service
root@k8s-master-1:/home/ubuntu# export KUBECONFIG=/etc/kubernetes/admin.conf root@k8s-master-1:/home/ubuntu# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master-1 Ready control-plane 5m55s v1.24.1
ubuntu@k8s-master-1:~$ kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-master-1 Ready control-plane 4m52s v1.24.1
回滚操作
1 2 3 4 5 6
kubeadm reset [glags]
preflight Run reset pre-flight checks update-cluster-status Remove this node from the ClusterStatus object. remove-etcd-member Remove a local etcd member. cleanup-node Run cleanup node.
配置网络
这一步很关键,如不能正确配置集群网络,pod 间可能无法通讯,kubectl proxy 无法正常访问(通常表现为 pod 运行正常,但提示连接拒绝)。以 flannel 为例,首先安装 flannel。
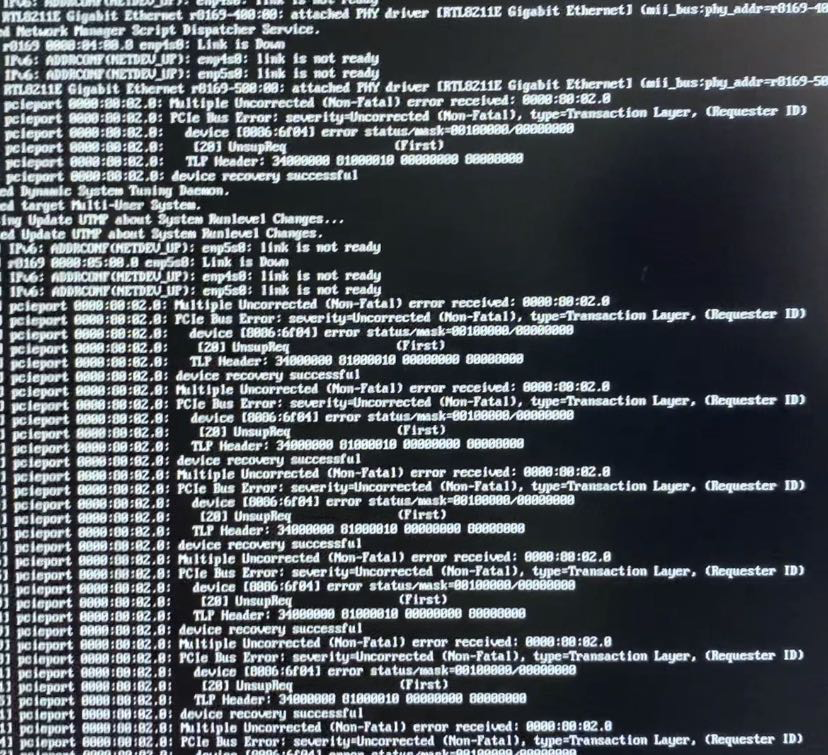
this means that the api server cannot be connected. could be caused by a number of things (including firewall).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
root@k8s-master-1:~# service docker status ● docker.service - Docker Application Container Engine Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2022-06-08 16:30:32 UTC; 34min ago TriggeredBy: ● docker.socket Docs: https://docs.docker.com Main PID: 1039 (dockerd) Tasks: 23 Memory: 134.1M CGroup: /system.slice/docker.service └─1039 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
Jun 08 17:04:52 k8s-master-1 dockerd[1039]: time="2022-06-08T17:04:52.874831490Z" level=error msg="Handler for POST /v1.40/images/create returned error: Get \"https://k8s.gcr.io/v2/\": context deadline exceeded" Jun 08 17:04:58 k8s-master-1 dockerd[1039]: time="2022-06-08T17:04:58.867350258Z" level=warning msg="Error getting v2 registry: Get \"https://k8s.gcr.io/v2/\": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)" ...
设置 --image-repository可以拉下来镜像,但还是会在启动 control plane 时超时。
1 2
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [kubelet-check] Initial timeout of 40s passed.
# 报错 [ERROR] Failed to execute goal com.github.eirslett:frontend-maven-plugin:1.3:npm (npm install) on project ambari-admin: Failed to run task: 'npm install --unsafe-perm' failed. (error code 1) -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException [ERROR] [ERROR] After correcting the problems, you can resume the build with the command [ERROR] mvn <args> -rf :ambari-admin # 处理 cd ambari-admin/src/main/resources/ui/admin-web npm install --unsafe-perm # 继续打包 mvn -B clean install rpm:rpm -DnewVersion=2.7.5.0.0 -DbuildNumber=5895e4ed6b30a2da8a90fee2403b6cab91d19972 -DskipTests -Drat.skip=true -Dpython.ver="python >= 2.6" -rf :ambari-admin